Automated Root-Cause Diagnosis for GPU Training
RidgeScope reads your training telemetry and produces a grounded root-cause verdict — what failed, why, and what to do — without instrumenting your code.
- 12,000+ signals read per run
- 20+ failure modes
- No SDK or code changes
- Verdict in minutes
- Slurm-scheduled clusters

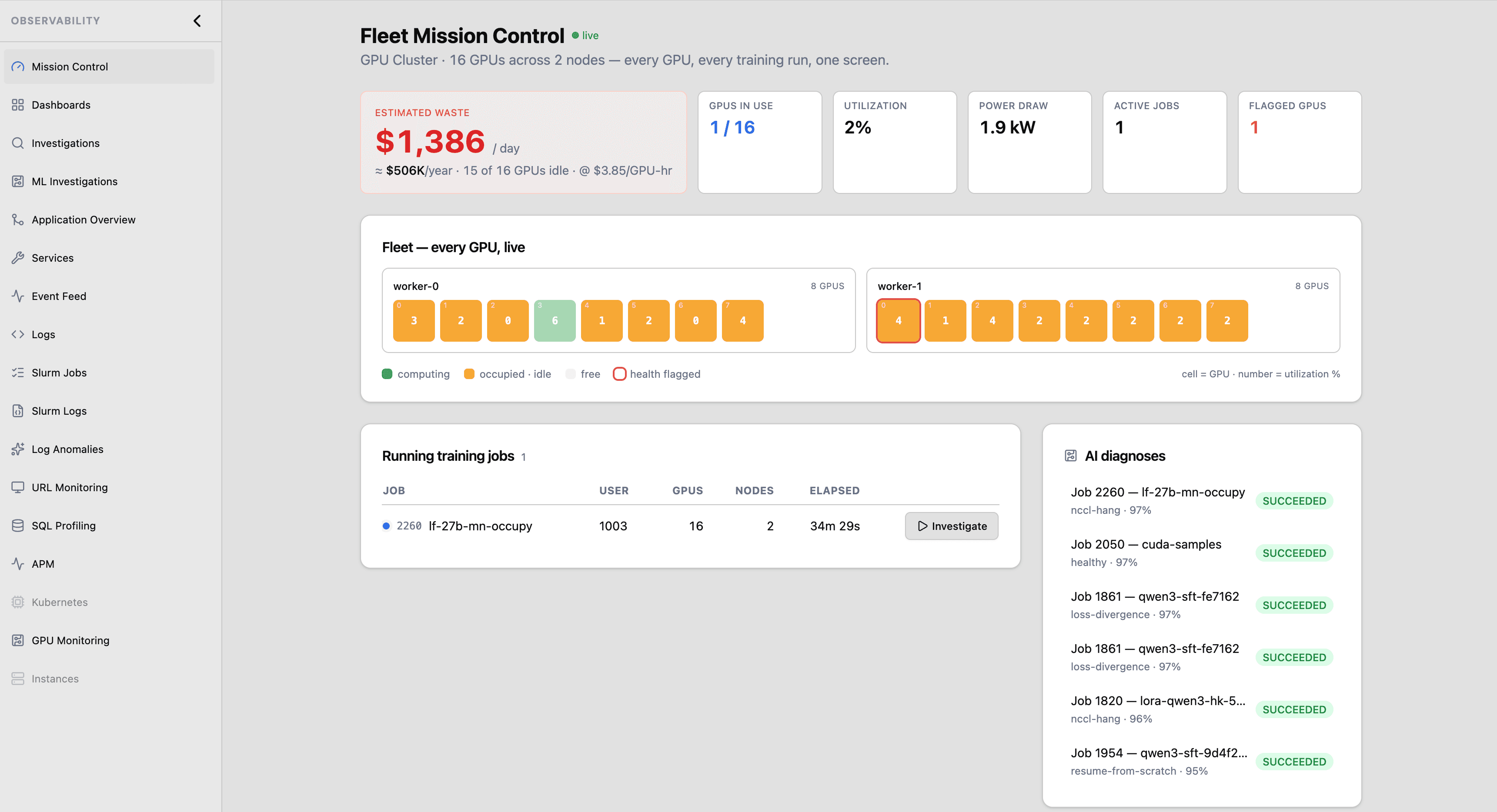
From a day of guessing to a verdict in minutes
to trace a slow or failed training run by hand — across logs, metrics, and the scheduler.
~$10,000 of wasted GPU on a 128-GPU cluster while you investigate.
to a grounded root-cause verdict — what failed, why, and what to do — cited to the exact metric and log.

→ Assumes ~$1 / GPU-hour, on-demand · a 128-GPU cluster = $128 of compute per day.
Zero instrumentation.
Evidence from every layer.
A lightweight on-node agent collects across the stack — no SDK, no code changes, no special logging sink.
GPU telemetry
Memory & allocation curves, engine-active vs SM-active duty cycle, XID / ECC / thermal health.
CUDA & NCCL tracing (eBPF)
Kernel launch counts, API durations, in-flight collectives — separation of idle hang from real compute.
Job logs
Loss trajectory, framework progress, Python tracebacks — attributed by rank, node, and process.
Slurm scheduler records
Job & step lifecycle, per-node epilogue/prolog exit codes — encode failure isn't read as a code fault.

No single signal is trusted alone — the verdict is only as strong as the evidence that agrees across stores.
Every signal the verdict is allowed to cite, in one public catalog — browse the Evidence Index
A verdict you can act on —
with the evidence

“Job 2260 is currently hung inside an NCCL collective and will not recover without intervention.”
- Every claim cited to a metric and log.
- Recommended action, not just a diagnosis.
- Names what it cannot decide — no guessing.
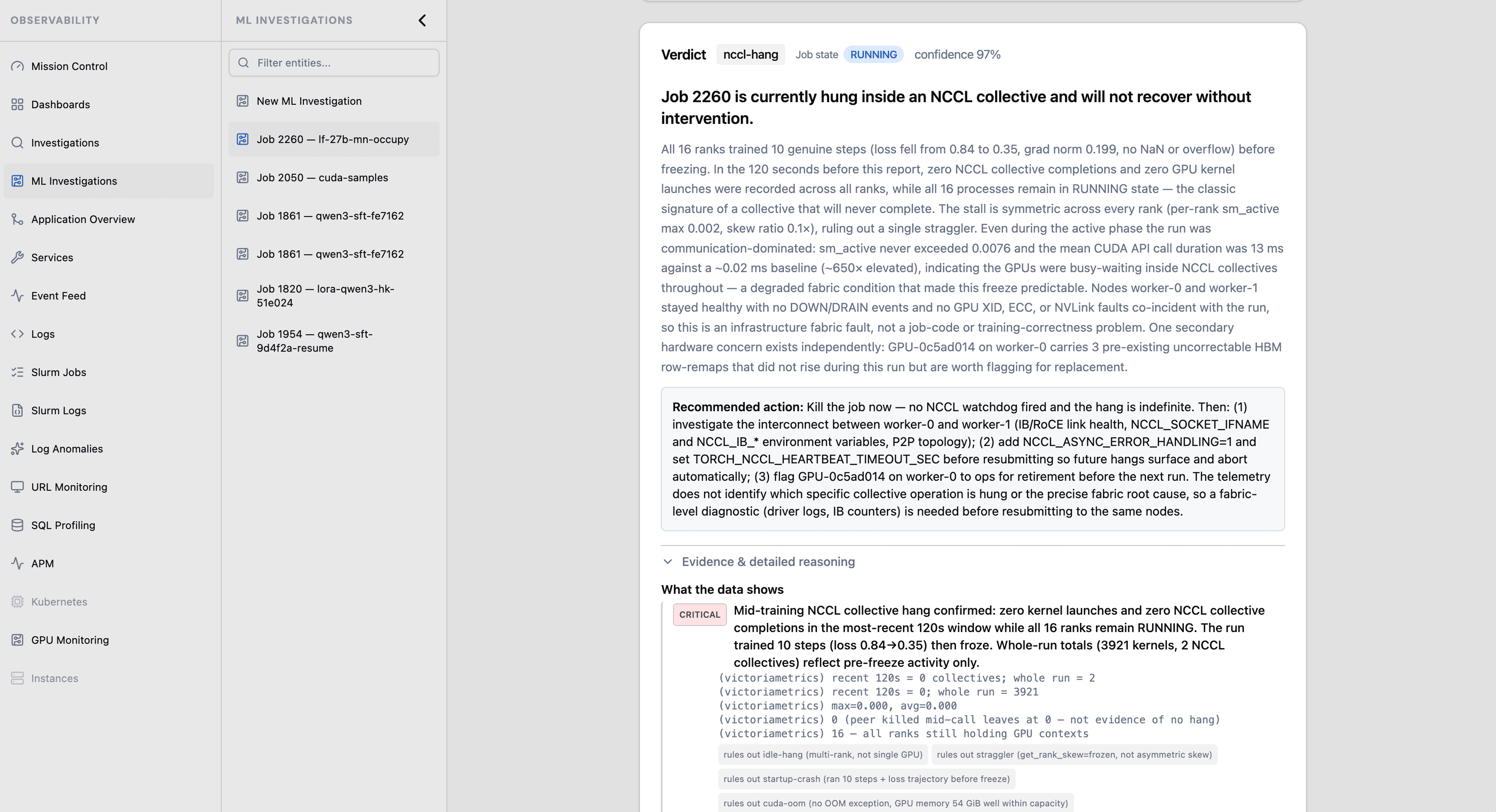
Anatomy of a verdict
Every investigation ends in a three-part verdict — what the data shows, what it implies, and what it cannot decide — plus a single failure family and a confidence score. Here is a real “done-but-bad” case: the run that succeeded and learned nothing.
What the data shows
The run completed cleanly and the GPUs were healthy — but the loss rose, then dead-plateaued near 11.9, with the gradient norm trending to zero. Every infrastructure tool read “healthy” until the loss was read.
What it implies
Loss divergence — a training-correctness failure, not an infrastructure one. The whole allocation produced a model that learned nothing, and because it completed cleanly, nothing else flagged it. The tell is the shape of the loss.
What it cannot decide
Whether the root cause is the learning-rate schedule, mixed-precision instability, or dataset integrity — the configuration behind the trajectory is not in the telemetry. The verdict says so, instead of guessing.
The third part is the one no other tool writes: the verdict states its limits honestly, so an engineer can trust and act on it.
We catch the runs other tools call ”healthy”
The dangerous failures are “done-but-bad” — the job completes cleanly, so infrastructure tools read green. ApexData judges on positive evidence, across four families.

Throughput & utilization
GPU under-utilization, I/O save-storms, stragglers — one slow rank drags the whole multi-GPU allocation.
Training correctness
Loss divergence, silent resume-from-scratch (checkpoint never loaded), underestimated runs.
Cluster & scheduler
Node-down mid-run, requeue / preemption, timeout — a job fault vs. an infrastructure event.
Healthy baseline
Confirms a genuinely healthy run on positive evidence, not on the absence of errors.
+ 3 more families covered (Startup & config · GPU memory & hardware · Distributed coordination) — every mode is named and ruled in or out with counterfactuals.
Browse the full failure catalog
The only system that reads the training itself
Infrastructure tools read infrastructure health. RidgeScope reads the run — 12,000+ signals per training run, from the loss trajectory to per-rank collectives — and ends every run with a verdict, not a dashboard.
| Capability | RidgeScope | Datadog GPU | DCGM + Grafana | NVIDIA Mission Control |
|---|---|---|---|---|
| GPU telemetry (utilization, ECC, thermals) | ✓ | ✓ | ✓ | ✓ |
| Reads the loss trajectory from job output | ✓ | — | — | — |
| Per-rank CUDA & NCCL tracing — no SDK, no code changes | ✓ | — | — | — |
| Detects “done-but-bad” runs (completed cleanly, learned nothing) | ✓ | — | — | — |
| Plain-English root-cause verdict with cited evidence | ✓ | — | — | — |
| Separates a job fault from an infrastructure fault, per run | ✓ | — | — | — |
| Names what it cannot decide | ✓ | — | — | — |
Based on publicly documented capabilities of each product, July 2026.
Frameworks & training stacks we recognize
The agent reads loss, gradient norm, learning rate, and checkpoints directly from each job's standard output, via a registry of framework-specific parsers.
Hugging Face Transformers
Full ecosystem incl. the fine-tuning & alignment stack.
Megatron-LM
Full ecosystem incl. large-scale tensor and pipeline-parallel workloads.
PyTorch Lightning
Full trainer lifecycle, step- and epoch-level telemetry parsing.
Keras / TensorFlow
Callback-level and fit-loop telemetry for TF2 and Keras training runs.
Coverage comes from parsers, not from SDKs the team has to install.
PCI DSS & GDPR · On-prem / air-gapped · SSO / SAML · Per-tenant isolation · Local LLMs — telemetry never leaves your environment
Questions, answered
How is this different from Datadog or Grafana?
They read infrastructure health and hand you dashboards and a query language. RidgeScope reads the training itself — the loss trajectory, per-rank CUDA/NCCL activity, scheduler records — and ends every run with a root-cause verdict, cited to the exact metric and log. A run that completes cleanly but learned nothing reads green everywhere else; we catch it.
Do we need to change our training code?
No. A lightweight on-node agent collects everything — GPU telemetry, eBPF-level CUDA/NCCL traces, job stdout, Slurm records. No SDK, no code changes, no special logging sink, no access to your training code required.
How fast do we see value?
The agent installs in minutes across a Slurm-scheduled cluster. The first root-cause verdict lands within 30 minutes — compared to up to a day of tracing a failed run by hand.
Can it run on-prem or air-gapped?
Yes. On-premise and air-gapped deployments are supported, with local LLMs so telemetry never leaves your environment. PCI DSS & GDPR, SSO/SAML, encryption at rest and in transit, and strict per-tenant isolation.
Which training stacks are recognized?
Hugging Face Transformers (including TRL, LLaMA-Factory, Axolotl), Megatron-LM, PyTorch Lightning, and Keras/TensorFlow — via a registry of framework-specific parsers, not SDKs. Runs are scheduled by Slurm; fully custom training loops are honestly reported as “unverifiable” rather than guessed at.
What happens when the agent cannot decide?
It says so. Every verdict has a third part — “what it cannot decide” — that states the limits of the evidence instead of guessing. A verdict an engineer can trust is one that names its own uncertainty.



